
My name is Haowen Bai (白浩闻). I am currently a Postdoctoral Research Fellow at Nanyang Technological University, Singapore, supervised by Prof. Yap Kim Hui.
I received my Ph.D. degree in Statistics from School of Mathematics and Statistics, Xi’an Jiaotong University, supervised by Prof. Jiangshe Zhang and worked closely with Dr. Zixiang Zhao and Prof. Shuang Xu.
My research focuses on low-level computer vision and multi-source information fusion, with a particular emphasis on multi-modal image fusion and restoration.
Email:
haowen.bai (at) ntu.edu.sg
haowen.bai (at) hotmail.com
hwbaii (at) stu.xjtu.edu.cn (will expire)
🔥 News
- 2025.09: One paper on video fusion is accepted by NeurIPS 2025 (Spotlight).
- 2025.06: Two papers are accepted by ICCV 2025 (One on retinex-based image fusion and the other on hyper-spectral image restoration).
- 2025.02: One paper on multi-modality image fusion is accepted by CVPR 2025 (Highlight).
📖 Education and Experience
- 2025.12 - Present, Research Fellow, School of Electrical Electronic Engineering, Nanyang Technological University.
- 2020.09 - 2025.09, Ph.D. in Statistics, Xi’an Jiaotong University.
- 2016.09 - 2020.06, B.S. in Information and Computing Science, Dalian University of Technology.
📝 Publications
First-Author
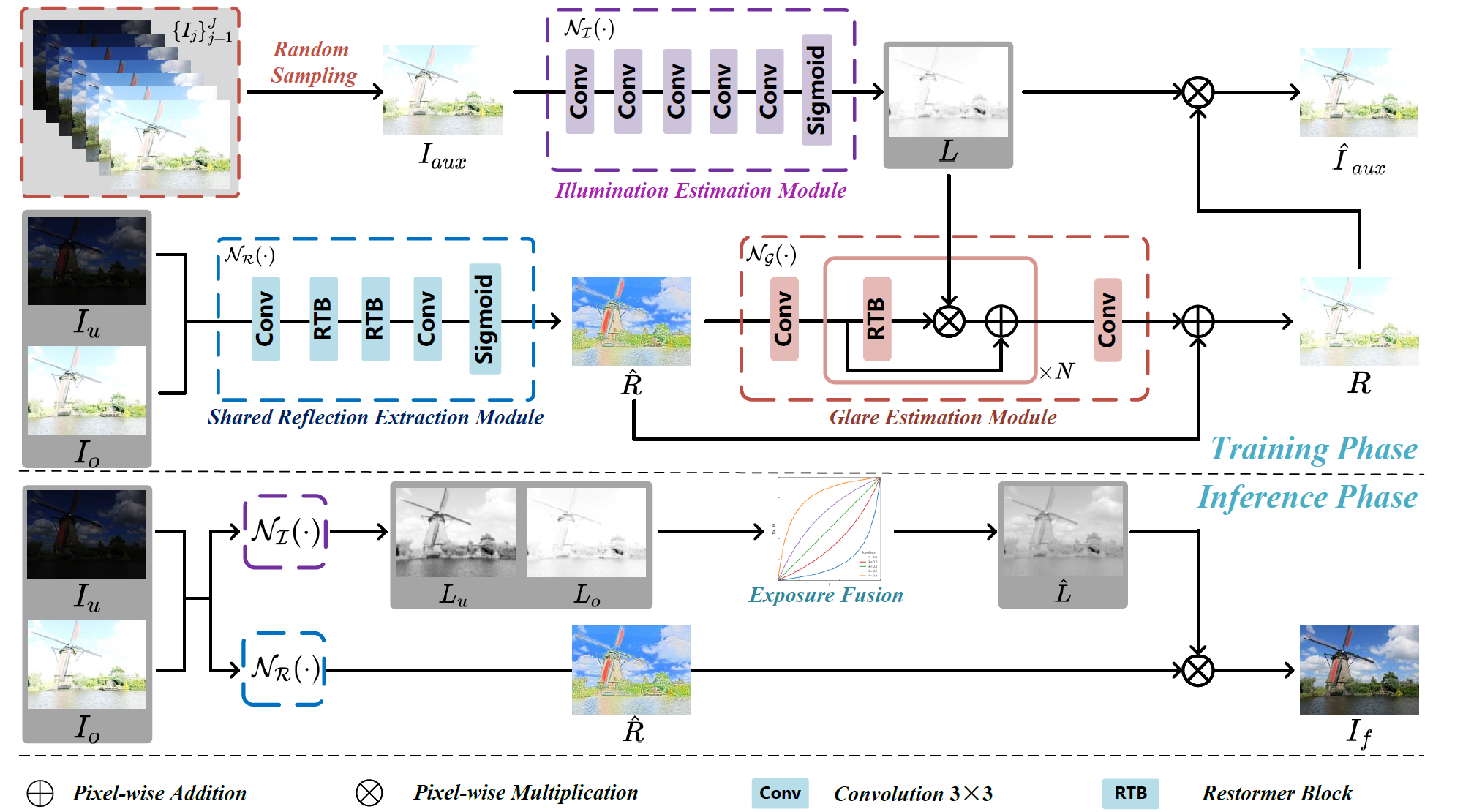
Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion
IEEE/CVF International Conference on Computer Vision (ICCV), 2025.
Haowen Bai, Jiangshe Zhang*, Zixiang Zhao*, Lilun Deng, Yukun Cui, Shuang Xu
- Retinex Theory–Based Adaptive Solution for Multi-Exposure Image Fusion, by modeling glare effects to adapt to overexposed conditions.
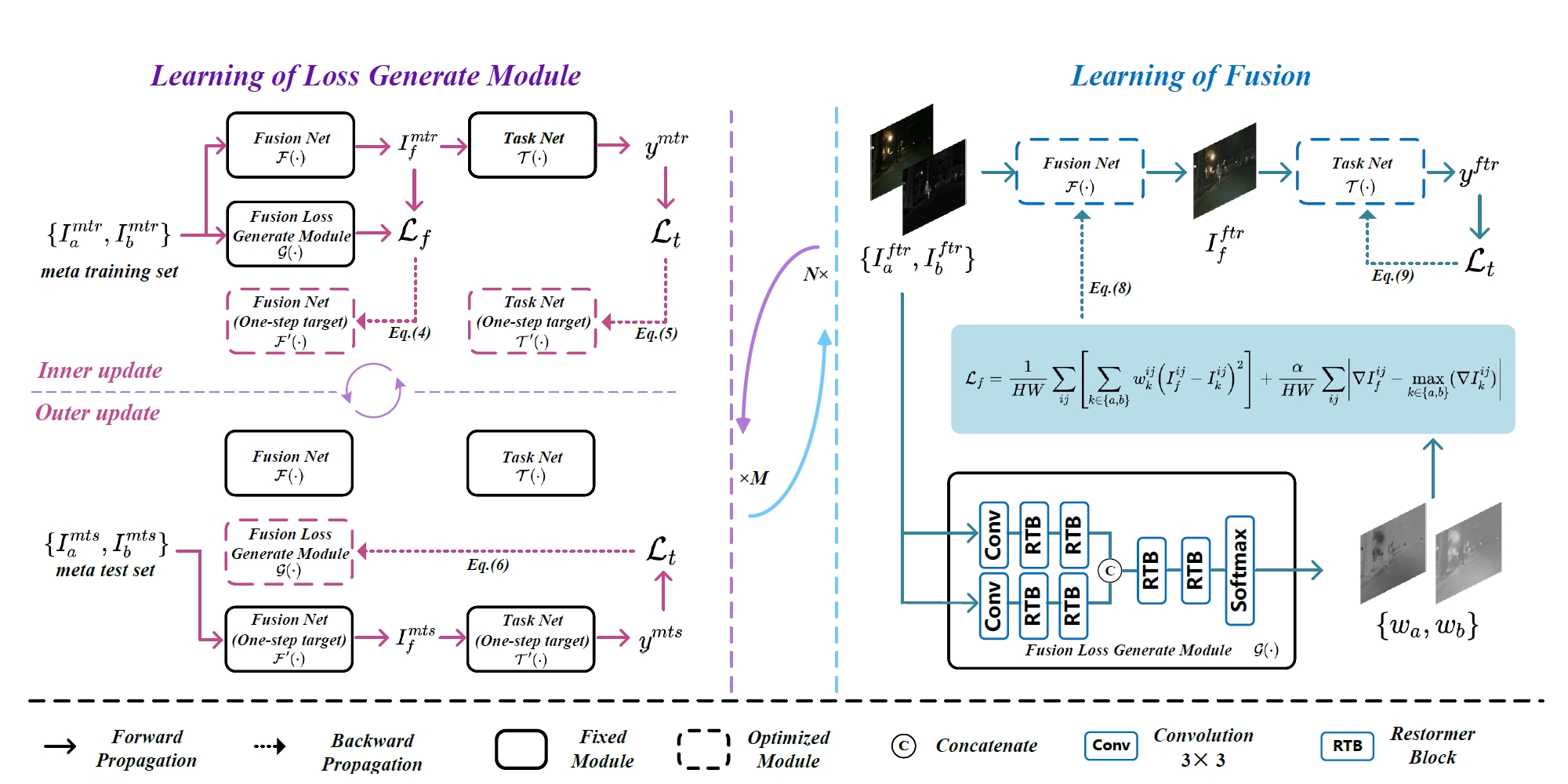
Task-driven Image Fusion with Learnable Fusion Loss
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. (Highlight)
Haowen Bai, Jiangshe Zhang*, Zixiang Zhao*, Yichen Wu, Lilun Deng, Yukun Cui, Tao Feng, Shuang Xu
- A task-driven image fusion framework that employs a learnable fusion loss guided by downstream task objectives through meta-learning, enabling adaptive fusion optimization for improved performance in downstream tasks.
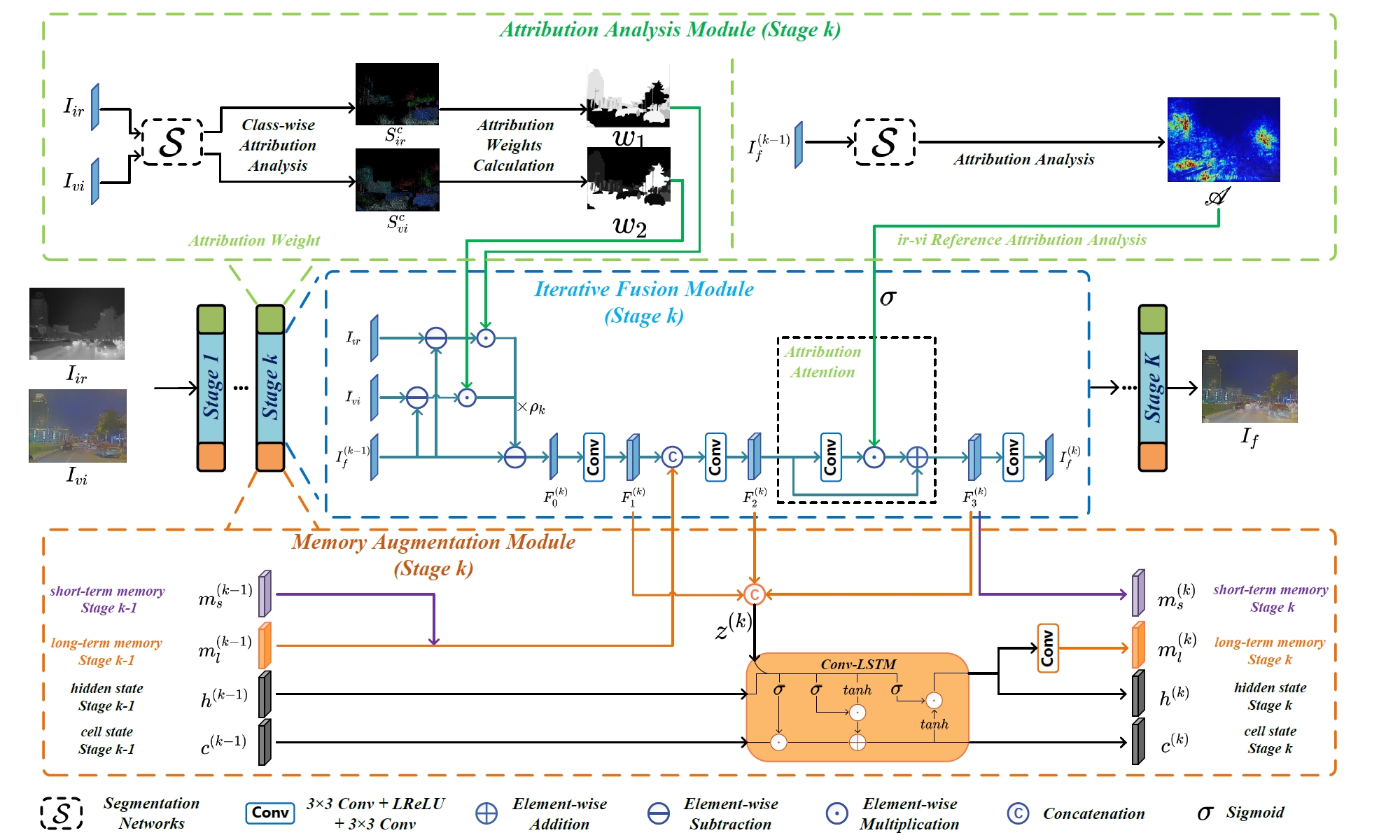
Deep Unfolding Multi-modal Image Fusion Network via Attribution Analysis
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 35(4), pp. 3498-3511, 2025.
Haowen Bai, Zixiang Zhao, Jiangshe Zhang*, Baisong Jiang, Lilun Deng, Yukun Cui, Shuang Xu, Chunxia Zhang
- An attribution-guided fusion framework that optimizes multi-modal image synthesis for semantic segmentation via unfolding networks and adaptive loss design, prioritizing task-critical features through attribution maps.
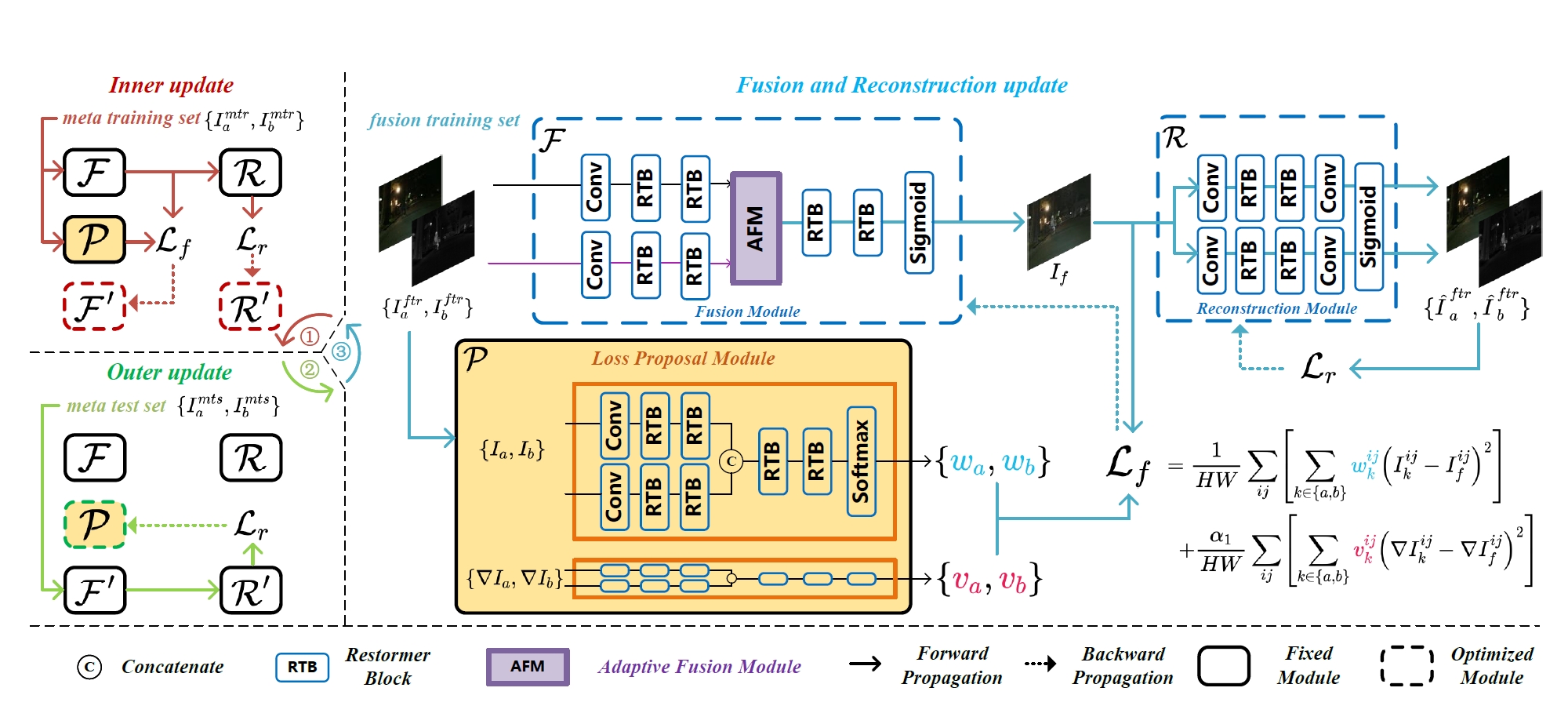
ReFusion: Learning Image Fusion from Reconstruction with Learnable Loss Via Meta-Learning
International Journal of Computer Vision (IJCV), pp.1-23, 2024.
Haowen Bai, Zixiang Zhao*, Jiangshe Zhang*, Yichen Wu, Lilun Deng, Yukun Cui, Baisong Jiang, Shuang Xu
- Propose a meta-learning-based image fusion framework that dynamically optimizes task-specific loss functions through source image reconstruction to preserve optimal source information.
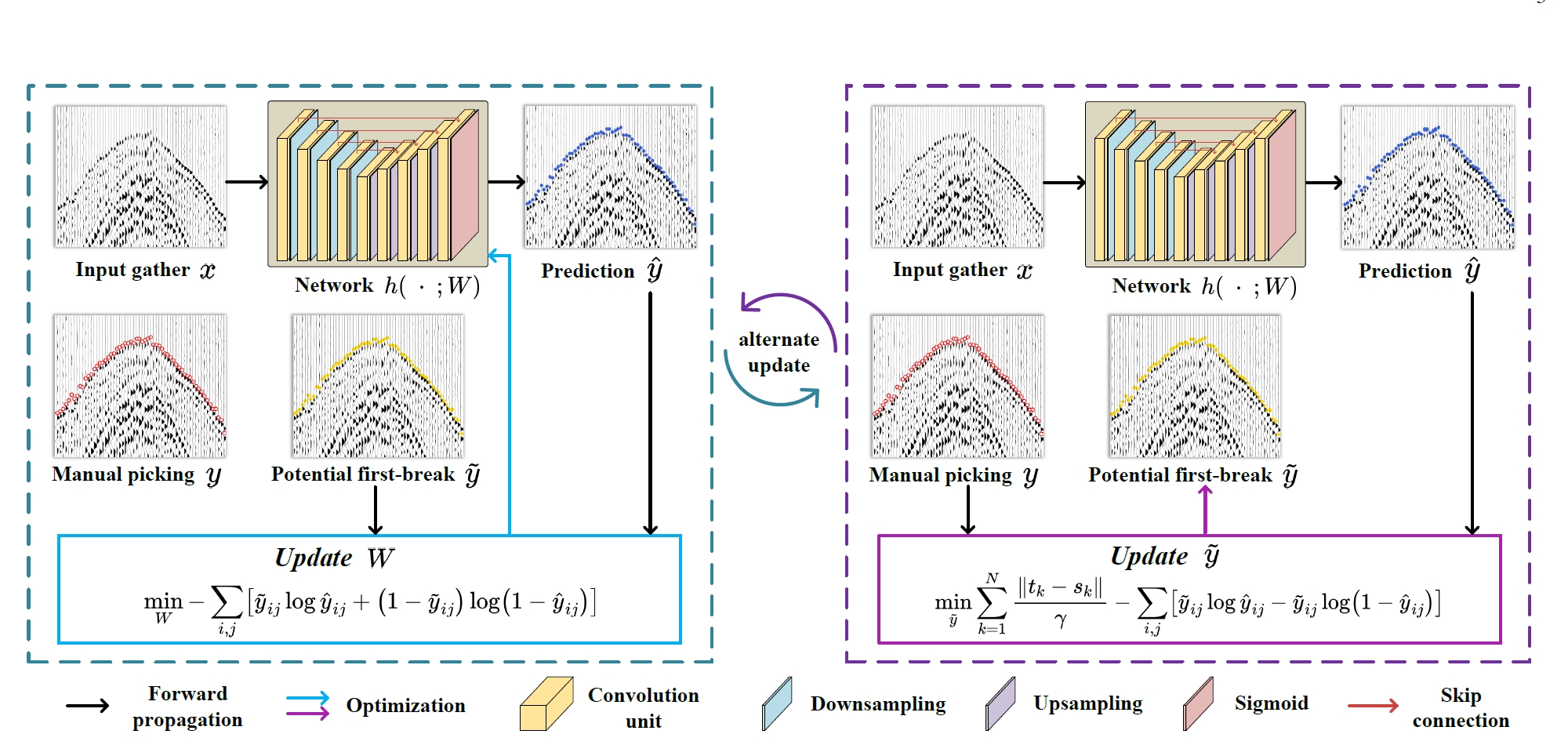
Simultaneous Automatic Picking and Manual Picking Refinement for First-Break
IEEE Transactions on Geoscience and Remote Sensing (TGRS), 62, pp. 1-12, 2024.
Haowen Bai, Zixiang Zhao, Jiangshe Zhang*, Yukun Cui, Chunxia Zhang*, Zhenbo Guo, Yongjun Wang
- Propose a novel approach that jointly optimizes label refinement and first-break picking performance in microseismic data by integrating a latent variable representation of true first-break times into a probabilistic model.
Collaborative Works
-
NeurIPS 2025(Spotlight) A Unified Solution to Video Fusion: From Multi-Frame Learning to Benchmarking.
Neural Information Processing Systems (NeurIPS), 2025.
Zixiang Zhao, Haowen Bai, Bingxin Ke, Yukun Cui, Lilun Deng, Yulun Zhang, Kai Zhang, Konrad Schindler
Project Page | Paper | ArXiv | Code -
ICCV 2025Hipandas: Hyperspectral Image Joint Denoising and Super-Resolution by Image Fusion with the Panchromatic Image
IEEE/CVF International Conference on Computer Vision (ICCV), 2025.
Shuang Xu, Zixiang Zhao, Haowen Bai, Chang Yu, Jiangjun Peng, Xiangyong Cao, Deyu Meng
Paper | ArXiv | Code -
ICML 2024Image fusion via vision-language model
Forty-first International Conference on Machine Learning (ICML), 2024.
Zixiang Zhao, Lilun Deng, Haowen Bai, Yukun Cui, Zhipeng Zhang, Yulun Zhang, Haotong Qin, Dongdong Chen, Jiangshe Zhang, Peng Wang, Luc Van Gool
Project Page | Paper | ArXiv | Code
CVPR 2024Equivariant multi-modality image fusion
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
Zixiang Zhao, Haowen Bai, Jiangshe Zhang, Yulun Zhang, Kai Zhang, Shuang Xu, Dongdong Chen, Radu Timofte, Luc Van Gool
Paper | ArXiv | Code
ICCV 2023(Oral) DDFM: denoising diffusion model for multi-modality image fusion
IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
Zixiang Zhao, Haowen Bai, Yuanzhi Zhu, Jiangshe Zhang, Shuang Xu, Yulun Zhang, Kai Zhang, Deyu Meng, Radu Timofte, Luc Van Gool
Paper | ArXiv | Code
-
CVPR 2023CDDfuse: Correlation-Driven Dual-branch feature decomposition for multi-modality image fusion
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
Zixiang Zhao, Haowen Bai, Jiangshe Zhang, Yulun Zhang, Shuang Xu, Zudi Lin, Radu Timofte, Luc Van Gool
Paper | ArXiv | Code -
CVPRW 2023Deep convolutional sparse coding networks for interpretable image fusion
IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2023.
Zixiang Zhao, Jiangshe Zhang, Haowen Bai, Yicheng Wang, Yukun Cui, Lilun Deng, Kai Sun, Chunxia Zhang, Junmin Liu, Shuang Xu
Paper | Code
🌐 Services
Conference Reviewer:
- CVPR, ICCV, AAAI, NeurIPS, WACV, …
Journal Reviewer:
- International Journal of Computer Vision (IJCV)
- IEEE Transactions on Image Processing (TIP)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
- Information Fusion
- ISPRS Journal of Photogrammetry and Remote Sensing
- Knowledge-Based Systems
- Neurocomputing
- Computer Methods and Programs in Biomedicine
- …